Ever experienced a sudden blackout, a crashing app, or a factory grinding to a halt? That’s system failure in action—unpredictable, disruptive, and often costly. In our hyper-connected world, understanding why systems fail is no longer optional.
What Is System Failure? A Clear Definition

At its core, a system failure occurs when a system—whether mechanical, digital, organizational, or biological—ceases to perform its intended function. This can range from a minor glitch to a catastrophic collapse. The term applies across industries, from IT networks to power grids and healthcare infrastructures.

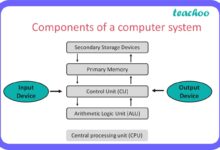
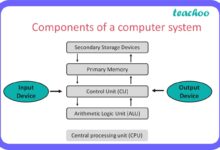
Types of System Failures
Not all system failures are created equal. They vary in scope, impact, and origin. Understanding the types helps in diagnosing and preventing future issues.
- Complete Failure: The system stops working entirely—like a server crash during peak traffic.
- Partial Failure: Some components work, but overall performance degrades—e.g., a website loading slowly due to database lag.
- Intermittent Failure: Problems occur sporadically, making diagnosis difficult—common in software with memory leaks.
Common Examples in Daily Life
System failure isn’t just a technical term—it’s something we encounter regularly, often without realizing it.
- A smartphone freezing during a call.
- ATMs going offline during a banking outage.
- Traffic lights malfunctioning, causing gridlock.
- Airline reservation systems crashing, stranding passengers.
“Failures are finger posts on the road to achievement.” – C.S. Lewis
Root Causes of System Failure
Behind every system failure lies a chain of causes—some obvious, others hidden. Identifying these root causes is essential for building resilient systems.
Human Error and Mismanagement
One of the most common causes of system failure is human error. This includes incorrect configuration, poor decision-making, or lack of training.
- Accidental deletion of critical files by an administrator.
- Improper system upgrades leading to incompatibility.
- Failure to follow standard operating procedures (SOPs).
According to a 2023 IBM report, human error contributes to nearly 23% of data breaches—many of which stem from system misconfigurations.
Technical and Design Flaws
Poor system architecture or flawed design can doom a system from the start. These issues often remain undetected until stress conditions arise.
- Inadequate load balancing in cloud systems.
- Single points of failure in network design.
- Use of outdated or unpatched software libraries.
For example, the Mariner 1 space mission failed in 1962 due to a single missing hyphen in the code—a classic case of a technical flaw with massive consequences.
External Shocks and Environmental Factors
Sometimes, system failure is triggered by forces beyond human control.
- Natural disasters like earthquakes or floods damaging data centers.
- Power outages disrupting hospital life-support systems.
- Cyberattacks exploiting vulnerabilities during peak usage.
The 2003 Northeast Blackout, which affected 55 million people, began with a software bug in an Ohio control room, but was exacerbated by high temperatures and overgrown trees—showing how environmental and technical factors can combine in a system failure.
System Failure in Technology and IT Infrastructure
In the digital age, IT systems are the backbone of nearly every organization. When they fail, the ripple effects can be enormous.
Server Crashes and Downtime
Servers are the engines of the internet. When they crash, websites go dark, transactions halt, and trust erodes.
- Overloaded servers during flash sales (e.g., Black Friday crashes).
- Hardware failures like disk corruption or memory leaks.
- Software bugs causing infinite loops or denial-of-service conditions.
Amazon’s 2017 S3 outage, caused by a typo during a debugging session, cost businesses an estimated $150 million in lost revenue—highlighting how fragile even the most robust systems can be.
Software Bugs and Glitches
No software is perfect. Bugs are inevitable, but their impact depends on how they’re managed.
- Null pointer exceptions in code leading to app crashes.
- Concurrency issues in multi-threaded applications.
- Memory leaks that gradually consume system resources.
The Therac-25 radiation therapy machine is a tragic example—software bugs led to massive overdoses, resulting in patient deaths. This case remains a cornerstone in software engineering ethics.
Cybersecurity Breaches as System Failure
A cyberattack doesn’t just steal data—it can paralyze entire systems.
- Ransomware encrypting critical files and demanding payment.
- DDoS attacks overwhelming servers with fake traffic.
- Insider threats sabotaging internal networks.
The 2021 Colonial Pipeline hack, caused by a single compromised password, led to fuel shortages across the U.S. East Coast. It wasn’t just a data breach—it was a full-scale system failure with national implications.
System Failure in Critical Infrastructure
When essential services like power, water, or transportation fail, the consequences can be life-threatening.
Power Grid Failures
Electricity is the lifeblood of modern society. Grid failures can cascade across regions.
- Overload during peak demand leading to rolling blackouts.
- Failure of transmission lines due to weather or aging infrastructure.
- Lack of redundancy in grid design.
The 2019 Venezuela blackout, which lasted for days, was attributed to a combination of underinvestment, mismanagement, and possible sabotage—showing how political and technical factors can intertwine in a system failure.
Transportation System Breakdowns
From air traffic control to subway networks, transportation systems rely on precise coordination.
- Air traffic control software glitches delaying thousands of flights.
- Signal failures in rail systems causing derailments.
- Traffic management systems failing during rush hour.
In 2016, a software update glitch grounded United Airlines flights nationwide for over an hour. The issue? A corrupted database used for flight plans—a small error with massive operational impact.
Healthcare System Collapse
Hospitals depend on interconnected systems for patient care, records, and life support.
- EHR (Electronic Health Record) systems going offline during emergencies.
- Medical device malfunctions due to firmware bugs.
- Network failures disrupting telemedicine services.
During the early days of the pandemic, several hospitals experienced system failures due to sudden surges in patient data and remote access demands—exposing vulnerabilities in digital health infrastructure.
Organizational and Management System Failures
Not all system failures are technical. Often, the root cause lies in poor leadership, communication, or culture.
Communication Breakdowns
When teams can’t share information effectively, systems fail—even if the technology works perfectly.
- Lack of cross-departmental coordination in crisis response.
- Poor documentation leading to repeated errors.
- Failure to escalate critical issues up the chain of command.
The 1986 Challenger disaster was not just an engineering failure—it was a communication failure. Engineers had warned about O-ring risks in cold weather, but their concerns were not adequately conveyed to decision-makers.
Leadership and Decision-Making Errors
Poor leadership can override even the best-designed systems.
- Ignoring red flags to meet deadlines or budgets.
- Overconfidence in system reliability without stress testing.
- Failure to invest in maintenance and upgrades.
Enron’s collapse was a systemic failure of governance. Despite having advanced financial systems, leadership used them to hide debt and inflate profits—proving that ethical failure can be as damaging as technical failure.
Corporate Culture and Complacency
A culture that discourages reporting problems or rewards silence will eventually face catastrophic system failure.
- Employees afraid to report bugs or near-misses.
- Normalization of deviance—accepting small failures as normal.
- Lack of psychological safety in teams.
Boeing’s 737 MAX crisis was partly attributed to a culture that prioritized speed over safety. Whistleblowers were ignored, and software flaws in the MCAS system led to two fatal crashes.
How to Prevent System Failure: Best Practices
While not all failures can be prevented, many can be mitigated with proactive strategies.
Redundancy and Failover Mechanisms
Redundancy ensures that if one component fails, another can take over.
- Duplicate servers in different geographic locations.
- Backup power supplies like generators and UPS systems.
- Failover databases that automatically switch during outages.
Google’s global infrastructure uses redundancy at every level, allowing it to maintain 99.9% uptime even during regional disruptions.
Regular Maintenance and Updates
Preventive maintenance is cheaper and more effective than reactive fixes.
- Scheduled patching of software and firmware.
- Hardware inspections and replacements before failure.
- Performance monitoring to detect early warning signs.
The FAA mandates regular inspections for aircraft systems—because waiting for a failure is not an option in aviation.
Stress Testing and Simulation
Simulating extreme conditions helps identify weaknesses before they cause real-world failures.
- Chaos engineering: intentionally breaking systems to test resilience (used by Netflix).
- Disaster recovery drills for data centers.
- Load testing websites before major product launches.
Netflix’s Chaos Monkey tool randomly shuts down production instances to ensure the system can handle unexpected outages—proactive thinking at its best.
Case Studies of Major System Failures
History is filled with lessons from system failures. Studying them helps us build better systems.
The 2003 Northeast Blackout
One of the largest blackouts in history affected eight U.S. states and parts of Canada.
- Triggered by a software bug in FirstEnergy’s control room.
- Failed alarm system prevented operators from seeing the problem.
- Overgrown trees contacted power lines, causing a cascade.
The final report highlighted poor monitoring, lack of coordination, and inadequate system testing as key factors in the system failure.
The Knight Capital Trading Glitch
In 2012, a software deployment error caused Knight Capital to lose $440 million in 45 minutes.
- Old code was accidentally reactivated during an update.
- The system started buying stocks uncontrollably.
- The company nearly collapsed and was later acquired.
This case is now a textbook example of why automated trading systems need rigorous testing and rollback protocols.
The Fukushima Nuclear Disaster
A combination of natural disaster and system failure led to one of the worst nuclear accidents in history.
- An earthquake and tsunami disabled external power and backup generators.
- Cooling systems failed, leading to meltdowns.
- Design flaws underestimated the risk of such events.
The International Atomic Energy Agency (IAEA) later concluded that the disaster was preventable with better safety protocols and system redundancy.
The Future of System Resilience
As systems grow more complex, so must our approaches to preventing failure.
AI and Predictive Analytics
Artificial intelligence can detect anomalies before they lead to system failure.
- Machine learning models predicting server crashes based on usage patterns.
- AI monitoring network traffic for signs of cyberattacks.
- Predictive maintenance in manufacturing using sensor data.
Companies like Siemens use AI to monitor industrial equipment, reducing unplanned downtime by up to 50%.
Decentralized and Self-Healing Systems
The future lies in systems that can adapt and recover on their own.
- Blockchain-based networks that resist single points of failure.
- Autonomous drones rerouting during communication loss.
- Self-repairing software that patches vulnerabilities in real time.
Research in autonomic computing aims to create systems that manage themselves—like the human body regulating temperature or healing wounds.
Global Standards and Collaboration
No organization can prevent system failure alone. Global cooperation is key.
- International cybersecurity protocols like ISO 27001.
- Shared early warning systems for cyber threats.
- Cross-border power grid coordination to prevent blackouts.
The World Economic Forum’s Global Risks Report emphasizes the need for public-private partnerships to build systemic resilience against cascading failures.
What is a system failure?
A system failure occurs when a system—technical, organizational, or physical—stops performing its intended function, either partially or completely.
What are the most common causes of system failure?
The most common causes include human error, technical flaws, poor design, cyberattacks, natural disasters, and organizational mismanagement.
Can system failures be prevented?
While not all failures can be prevented, many can be mitigated through redundancy, regular maintenance, stress testing, and strong organizational culture.
How did the Therac-25 incident change software engineering?
The Therac-25 radiation overdoses led to stricter safety standards in medical software, emphasizing code review, fail-safes, and independent verification.
What is chaos engineering?
Chaos engineering is the practice of intentionally introducing failures into a system to test its resilience and improve reliability.
System failure is not just a technical glitch—it’s a multifaceted challenge that spans technology, human behavior, and organizational culture. From power grids to software platforms, the causes are diverse, but the lessons are universal. By understanding the root causes, learning from past mistakes, and adopting resilient design principles, we can build systems that withstand stress, adapt to change, and continue functioning when it matters most. The goal isn’t perfection—it’s preparedness.
Further Reading: